Which NYC subway lines have the longest wait times?
The chart below shows how long you should expect to wait for each train line, assuming you arrive on the platform at a random time on a weekday between 7:00 AM and 8:00 PM.
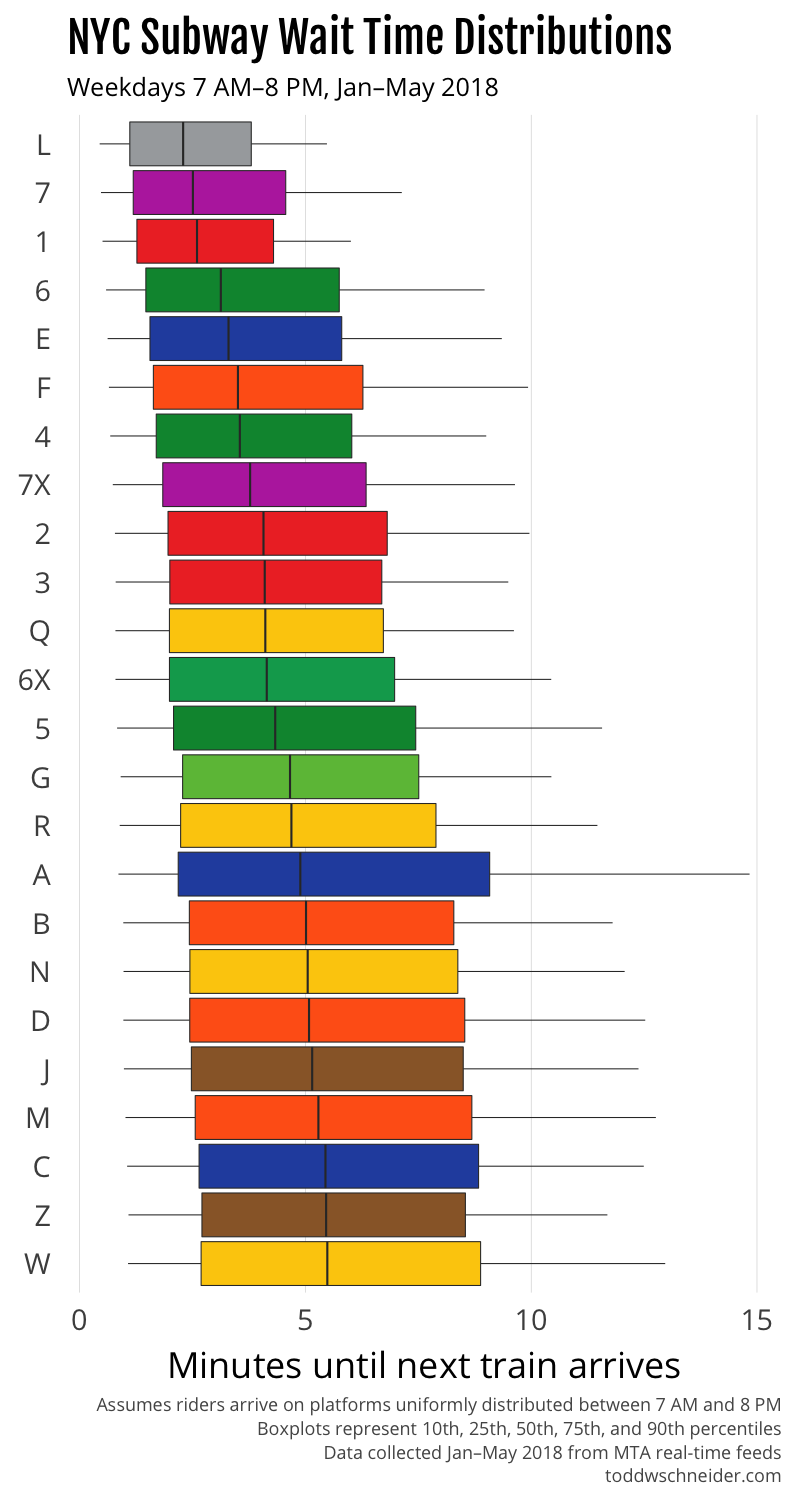
The top four trains with the shortest waits—the L, 7, 1, and 6—are the only trains that run on dedicated tracks, which presumably helps avoid delays due to trains from other lines merging in and out on different schedules. The L train is also the only line that uses modern communications-based train control (CBTC), which allows trains to operate in a more automated fashion. The 7 train, the second most reliable according to my data, is currently running “partial” CBTC, and is slated for full CBTC in 2018.
Systemwide CBTC is the cornerstone of the recently announced ambitious plan to fix the subways. I’ll have a bit more to say on that in a moment…
(Note that expected wait time is different from time between trains. See the appendix for a more mathematical treatment on converting between time between trains and expected wait time. Note also that in some cases, different lines can serve as substitutes. For example, if you’re traveling from Union Square to Grand Central, the 4, 5, and 6 lines will all get you there, so your effective wait time would be shorter than if you had to rely on one specific line.)
How long will you have to wait for your train?
The above graph is restricted to weekdays between 7:00 AM and 8:00 PM, but wait times vary from hour to hour. In general, wait times are shortest during morning and evening rush hours, though keep in mind that the data doesn’t know about cases where trains might be too crowded to board, forcing you to wait for the next train.
Choose your line below, and you can see how long you should expect to wait for a train by time of day, based on weekday performance from January to May 2018.

How crowded should you want the platform to be when you arrive?
Most New Yorkers intuitively understand that when they get to a subway platform, they don’t want it to be too empty or too crowded. An empty platform means that you probably just missed the last train, so it’s unlikely another one will be arriving very soon. Even worse, an extremely crowded platform means that something is probably wrong, and maybe the train will never arrive. There’s a Goldilocks zone in the middle: a healthy amount of crowding that suggests it’s been a few minutes since the last train, but not so long that things must be screwed up.
I used the same data to compute conditional wait time distributions: given that it’s been N minutes since the last train, how much longer should you expect to wait? In most cases, the shortest conditional wait time occurs when it’s been 5 to 8 minutes since the last train.
Choose your line to view conditional wait times.

In general when you arrive on the platform, you can’t directly observe when the last train departed, but you can make a guess based on the number of people who are waiting. First you would have to estimate—or maybe even measure from the MTA’s public turnstile data—the number of people who arrive on the platform each minute. Then, if you know the shortest conditional wait occurs when it’s been 6 minutes since the last train, and you estimated that, say, 20 people arrive on the platform each minute, you should hope to see 120 people on the platform when you arrive. Of course these parameters vary by platform and time of day, so make sure to take that into account when making your own estimates!
A back-of-the-envelope economic case for subway upgrades (that you shouldn’t take too seriously)
The recently released Fast Forward plan from Andy Byford, president of the NYC Transit Authority, proposes that it will take 10 years to implement CBTC across most of the system. The NYT further reports an estimated price tag of $19 billion.
If every line were as efficient as the CBTC-equipped L, I estimate that the average wait time would be around 3 minutes shorter. At 5.7 million riders per weekday, that’s potentially 285,000 hours of time saved per weekday. Reasonable people might disagree about the economic value of deadweight subway waiting time, but $20 per hour doesn’t strike me as crazy, and would imply a savings of $5.7 million per weekday. Weekends have about half as many riders as weekdays, and time is probably worth less, so let’s value a weekend day’s savings at 25% of a weekday’s.
Overall that would imply a total savings of over $1.6 billion per year, and that’s before accounting for the fact that CBTC-equipped trains also probably travel faster from station to station, so time savings would come from more than reduced platform wait times. And if people had more confidence in the system, they wouldn’t have to budget so much extra travel time as a safety buffer. Other potential benefits could come from lower operating and repair costs, and less above-ground traffic congestion if people switched from cars to the presumably more efficient subway.
To be fair, there are all kinds of things that could push in the other direction too: maybe it’s unrealistic that other lines would be as efficient as the L, since the L has the benefit of being on its own dedicated track that it doesn’t share with any other crisscrossing lines, or maybe the better subway would be a victim of its own success, causing overcrowding and other capacity problems. And perhaps the most obvious criticism: that the plan will end up taking longer than 10 years and costing more than $19 billion.
I don’t think this quick back-of-the-envelope calculation should be taken too seriously when there are so many variables to consider, but I do think it’s not hard to get to a few billion dollars a year in economic value, assuming some reasonable parameters. Reasonable people might again argue about discount rates and amortization schedules, but a total cost in the neighborhood of $19 billion over 10 years strikes me as eminently worth it.
Anatomy of a subway delay
The NYT recently published a great interactive story that demonstrated via simulation how a single train delay can cause cascading problems behind it. The week after that story was published, I was (un)fortunate enough to participate in a real-life demonstration of the phenomenon. On May 16, 2018, I found myself on a downtown F train from Midtown. Around 10:00 AM at 34th Street, the conductor made an announcement that there was a stalled train in front of us at W 4th Street, and that we’d be delayed. The delay lasted about 30 minutes, and then the train carried on as normal.
Here’s a graphical representation of downtown F trains that morning, with major delays highlighted in red. My train was the second train in the major delay on the right-center of the graph.

Although I wasn’t on the train that had mechanical problems at W 4th Street, my train and the two trains behind it were forced to wait for the problem train. Further back, the train dispatcher switched a few F trains to the express tracks from 47-50 Sts–Rockefeller Center to W 4th Street, which is why you see a few steeper line segments in the graph that appear to cut through the delay. The empty diagonal gash in the graph below the delay shows that riders felt the effects all the way down the line. If you were waiting for an F train at 2nd Avenue just after 10:00 AM, you would have had to wait a full 30 minutes, compared to only a few minutes if you had arrived on the platform at 9:55 AM.
I’m a bit surprised that the MTA didn’t deliberately slow down some of the trains in front of the delay. It’s well-known that even spacing is a key to minimizing system-wide wait time, the MTA once even made a video about it, but in this case it appears they didn’t practice what they preach. Slowing down a train in front of a delay will make some riders worse off, namely the ones at future stops who would have made the train had it not been slowed down. But it will also make some riders much better off: the ones who would have missed the train had it not been slowed down, and then had to suffer an abnormally long wait for the delayed train itself.
You can use the graph to convince yourself that slowing down the train ahead of the delay would have been a good thing. Downtown F trains stopped at 2nd Avenue at 9:58 and 10:00 AM. If the 10:00 AM train had been intentionally delayed 10 minutes to 10:10 AM, all of the people who arrived on the platform between 10:00 and 10:10 would have been saved from waiting until 10:30, an average 20 minute savings per person. On the other hand, the folks who arrived between 9:58 and 10:00 would have been penalized an average of 10 minutes per person. But there were likely five times as many people in the 10:00–10:10 range than there were in the 9:58–10:00 range, so the weighted average tells us we just saved an average of 15 minutes per person.
Compare the W 4th Street delay to the delay earlier that morning at 7:40 AM at 57th Street, highlighted on the left side of the graph. That delay, although shorter, also caused a lasting gap between trains. However, the gap was later mitigated when the train in front of the delayed train slowed down a bit between York and Jay streets. I suspect that slowdown was unintentional, but it was probably beneficial, and had it happened further up the line, say between 42nd and 34th streets, it would have produced more even spacing throughout the line, and likely lowered total rider wait time.
In fairness to the MTA, in real life it’s not as simple as “always slow down the train in front of the delay” because there are other considerations—dispatchers don’t know how long the delay will last, not every platform is equally popular, and there other options like rerouting trains to other tracks—but a healthier system could have dealt with this delay better.
Subway performance over time
The subway’s deteriorating performance has been covered at great length by many outlets. I’d recommend the NYT’s coverage in particular, but it seems like there are so many people writing about the subway recently that there’s no shortage of stories to choose from.
In addition to the dataset I collected starting in January 2018, the MTA makes some real-time snapshots available going back to September 2014. These snapshots are only available for the 1, 2, 3, 4, 5, 6, and L trains, and they’re in 5-minute increments as opposed to the 1-minute increments of my tracker. Additionally, there is a gap in historical coverage from November 2015 until January 2017.
The historical data shows that expected wait times have remained fairly unchanged since 2014, but travel times from station to station have gotten a bit slower, at least on the 2, 3, 4, and 5 trains, where a weekday daytime trip in 2018 takes 3-5% longer on average than the same trip in 2014. The 1 and 6 trains have not experienced similar slowdowns, and the L is somewhere in the middle.

On a 15-minute trip, 3-5% is an average of 30-45 seconds slower, which doesn’t sound particularly catastrophic, but there are plenty of other issues not reflected in these numbers that might make the subway “better” or “worse” over time. I’ve tried to exclude scheduled maintenance windows from the expected wait time calculations, but in reality scheduled maintenance and station closures can be a huge nuisance. The MTA data also doesn’t tell us anything about when trains are so crowded that they can’t pick up new passengers, when air conditioning systems are broken, and other general quality-of-ride characteristics.
It’s also possible that the 1-6 and L lines—the ones with historical data—happen to have deteriorated less than the other lettered lines, and if we had full historical data for the other lines, we’d see more dramatic effects over time. There’s no question that the popular narrative is that the subway has gotten worse in recent years, though part of me can’t help but wonder if the feedback loop provided by nonstop media coverage might be a contributing factor…
The NYC subway as a directed graph
I used the igraph package in R to construct a weighted directed graph of the subway system, where the nodes are the 472 subway stations, the edges are the various subway lines and transfers that connect them, and the weights are the expected travel times along each edge. For train edges, the weight is calculated as the median wait time on the platform plus the median travel time from station to station, and for transfer edges, the weight is taken from estimates provided by the MTA—typically 3 minutes if you have to change platforms, 0 if you don’t.
With the graph in hand, we can answer a host of fun (and maybe informative) questions, as igraph does the heavy lifting to calculate shortest possible paths from station to station across the system.
I used the directed graph to find the “center” of the subway system, defined as the station that has the closest farthest-away station. That honor goes to the Chambers Street–World Trade Center/Park Place station, from where you can expect to reach any other subway station in 75 minutes or less. Here’s a map highlighting the Chambers Street station, plus the routes you could take to the farthest reaches of Manhattan, Brooklyn, Queens, and the Bronx.

The directed graph might even be a good real estate planning tool. You might not care about the outer extremities of the city, but if you provide a list of neighborhoods you do frequent, the graph can tell you the most central station where you can minimize your worst-case travel times.
For example, if your personal version of NYC stretches from the Upper West Side to the north, Park Slope to the south, and Bushwick to the east, then the graph suggests W 4th Street in Greenwich Village as your subway center: you can get to all of your neighborhoods in a maximum of 26 minutes.

The graph can be used to calculate all sorts of other fun routes. I’ve seen attempts to find the longest possible subway trip that doesn’t involve any backtracking, which is all well and good, but what about finding the longest trip from A to B with the constraint that it’s also the fastest subway-only trip from A to B? Based on my calculations, the longest possible such trip stretches from Wakefield–241st Street in the Bronx to Far Rockaway–Beach 116th Street in Queens via the 2, 5, A, and Rockaway Park Shuttle. It would take a median time of 2:28—about as long as it takes the Acela to travel from Penn Station to Baltimore.

The fastest way to hit all 4 subway boroughs is from 138th St–Grand Concourse in the South Bronx to Greenpoint Avenue in North Brooklyn: 41 minutes via the 6, 4, E, and G trains. And the “centers” of each borough:
- Manhattan: 59th Street–Columbus Circle, 35 minutes max to any other stop in Manhattan
- Brooklyn: Jay Street–MetroTech, 45 minutes max to any other stop in Brooklyn
- Bronx: 149th Street–Grand Concourse, 41 minutes max to any other stop in the Bronx
- Queens: Halsey Street, 66 minutes max to any other stop in Queens
Further work
The directed graph is a bit silly: in many cases it wouldn’t make sense to rely only on the subway when other transportation options would be more sensible. I’ve written previously about taxi vs. Citi Bike travel times, and a logical extension would be to expand the edges of the directed graph to take into account more transportation options.
Of course, a more practical idea might be to use Google Maps travel time estimates, which already do some of the work combining subways, bikes, ferries, buses, cars, and walking. Still, there’s something nice about estimating travel times based on historical trips that actually happened, as opposed to using posted schedules.
There’s probably something interesting to learn by combining the MTA’s public turnstile data with the train location data. For example, the turnstiles might provide insights into when dispatchers should be more aggressive about maintaining even train spacing following delays. As the tracker collects more data, it might be interesting to see how weather affects subway performance, perhaps segmenting by routes that are above or below ground.
All eyes will be on the subway system in the months and years to come, as people wait to see how the current “fix the subway” drama unfolds. Hopefully the MTA’s real-time data can serve as a resource to measure progress along the way.
The code and how it works
Although there’s no official record of when trains actually stopped at each station, the MTA provides a public API of the real-time data that powers the countdown clocks, which can be used to estimate train performance.
Starting in January 2018, I’ve been collecting the countdown clock information every minute for every line in the NYC subway system, then calculating my best guesses as to when each train stopped at each station. Between January and May 2018, I observed some 900,000 trains that collectively made 24 million stops. The MTA’s data is very messy, and occasionally makes no sense at all, so I spent a considerable amount of time trying to clean up the data as best possible. For more technical details, including all of the code used in this post to collect and analyze the data, head over to GitHub.
The countdown clock system uses bluetooth receivers installed on trains and in stations: when a train passes through a station, it notifies the system of its most recent stop. The MTA has acknowledged the system’s less than perfect accuracy, but it’s much better than the status quo from only a few years ago when we really had no idea where the trains were.
Appendix: converting from “time between trains” to “expected wait time”
Putting aside messy data issues, the MTA’s real-time feeds tell us the amount of time between trains. But riders probably care more about how long they should expect to wait when they arrive at the platform, and those two quantities can be different.
As a hypothetical example, imagine a system where trains arrive exactly every 10 minutes on the 0s: 12:00, 12:10, etc. In that world, riders who arrive on the platform at 12:01 will wait 9 minutes for the next train, riders who arrive at 12:02 will wait 8 minutes, and so on down to riders who arrive at 12:09 who will wait 1 minute. If we assume a continuous uniform distribution of arrival times for people on the platform, the average person’s wait time will be one half of the time between trains, 5 minutes in this example.
Now imagine trains arrive alternating 5 and 15 minutes apart, e.g. 12:00, 12:05, 12:20, 12:25, etc., while people still arrive following a uniform distribution. The people who happen to arrive during one of the 5-minute gaps will average a 2.5 minute wait, while the people who arrive during one of the 15-minute gaps will average a 7.5 minute wait. The catch is that only 25% of all people will arrive during a 5-minute window while the other 75% will arrive during a 15-minute window, which means the global average wait time is now (2.5 * 0.25) + (7.5 * 0.75) = 6.25 minutes. That’s 1.25 minutes worse than the first scenario where trains were evenly spaced, even though in both scenarios the average time between trains is 10 minutes.
If you work out the math for the general case, you should find that average wait time is proportional to the sum of the squares of each individual gap between trains.

This means that given an average gap time, expected wait time will be minimized when the gaps are all identical. In practice, it very well could be worth increasing average gap time if it means you can minimize gap time variance. Looking back to our toy example, not only is the average of 52 and 152 greater than 102, it’s greater than 112, which means that trains spaced evenly every 11 minutes will produce less average wait time than trains alternating every 5 and 15 minutes, even though the latter scenario would have a shorter average gap between trains. For another take on this, I’d recommend Erik Bernhardsson’s NYC subway math post from 2016.
Often we want more than the expected wait time, we want the distribution of wait times, so that we can calculate percentile outcomes. Normally this is where I’d say something like “just write a Monte Carlo simulation”, but I think in this particular case it’s actually easier and more useful to do the empirical calculation.
Let’s say you have a list of the times at which trains stopped at a particular station, and you’d like to calculate the empirical distribution of rider wait times, assuming riders arrive at the platform following a uniform distribution. I’d reframe that problem as drawing balls out of a box, following the process below:
- Start with an empty box
- For each train, add N balls to the box, labeled 1 to N, where N is the number of seconds the train arrived after the train in front of it
Once you’ve done that, you’re pretty much done, as your box is now full of balls with numbers on them, and the probability of a rider having to wait some specific number of seconds t is equal to the number of balls labeled t divided by the total number of balls in the box. Note that you might want to filter trains by day of week or time of day, both because train schedules vary, and people don’t actually arrive on platforms uniformly, but if you restrict to within narrow enough time intervals, it’s probably close enough.
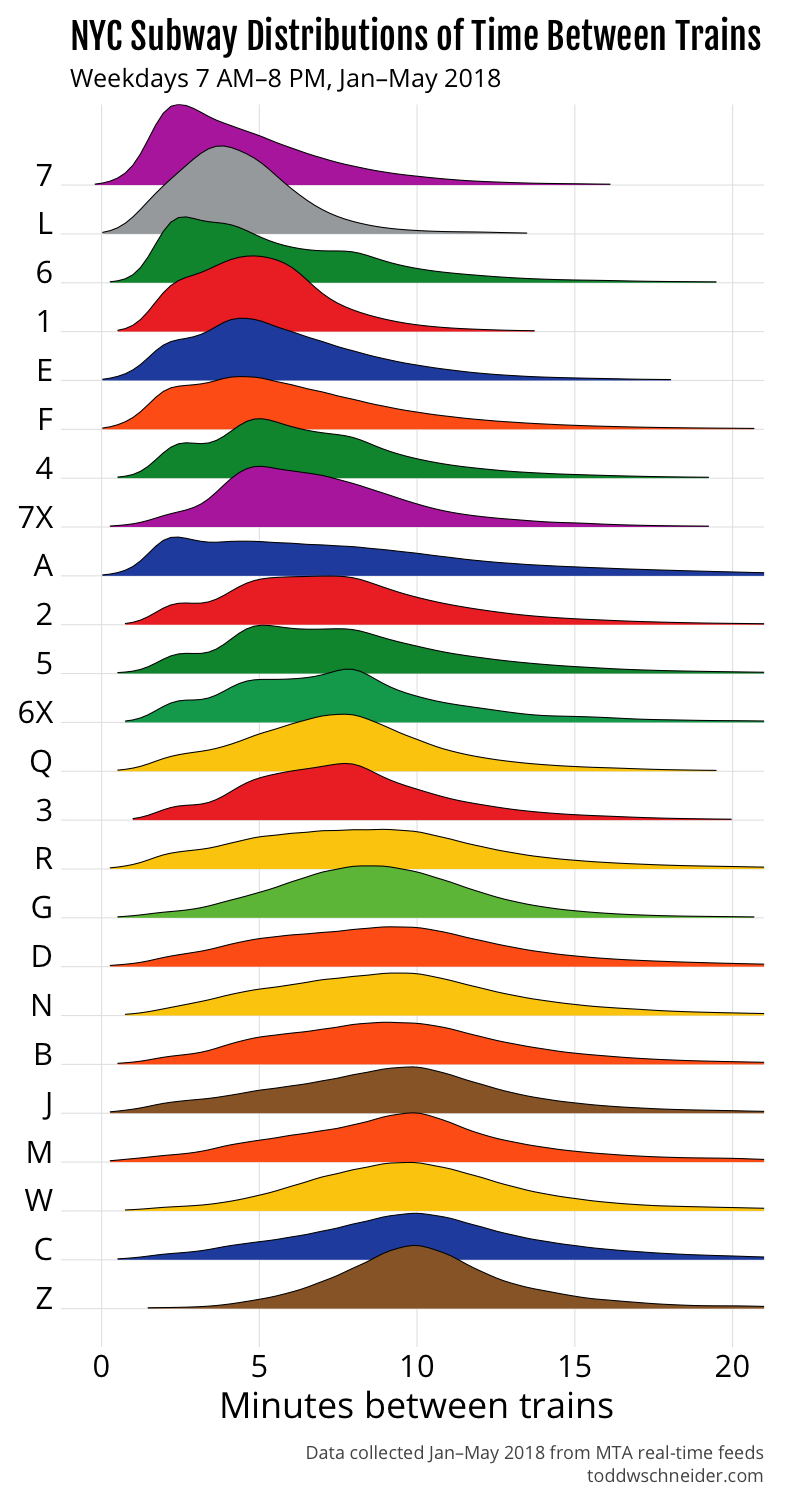
In terms of the actual NYC subway lines during weekdays between 7:00 AM and 8:00 PM, the 7 train has the shortest median time between trains, but the L does a better job at minimizing the occasional long gaps between trains, which is why we saw earlier that the L has shorter average wait times than the 7.
The A train has a notably flat and wide distribution, which explains why the first graph in this post showed that the A had the worst 75th and 90th percentile outcomes, even though its median performance is middle-of-the-pack.





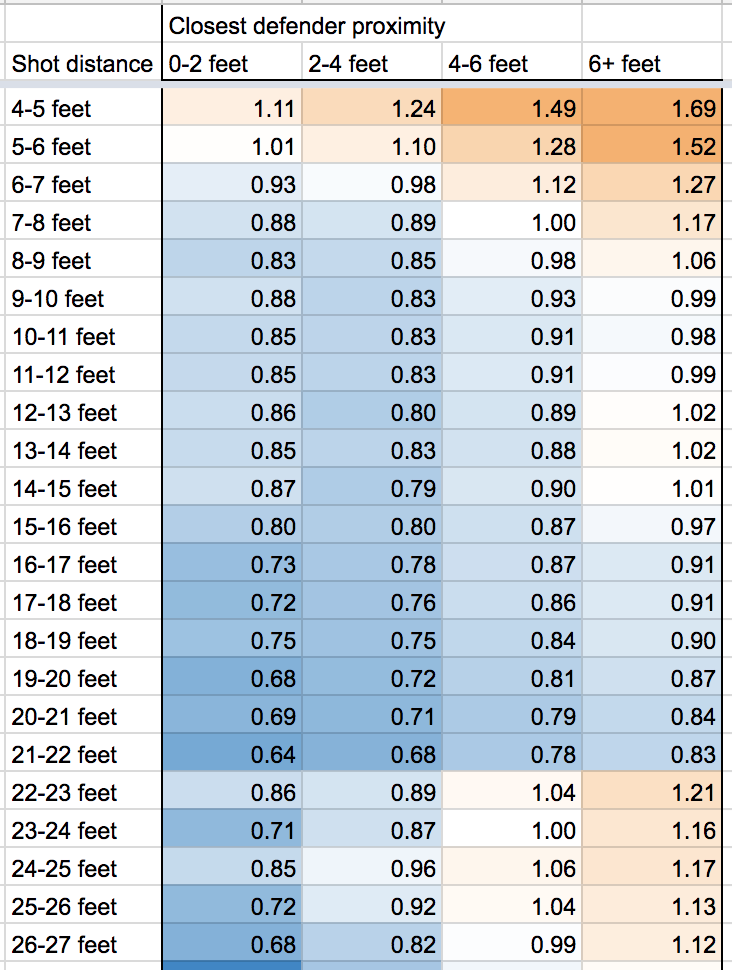
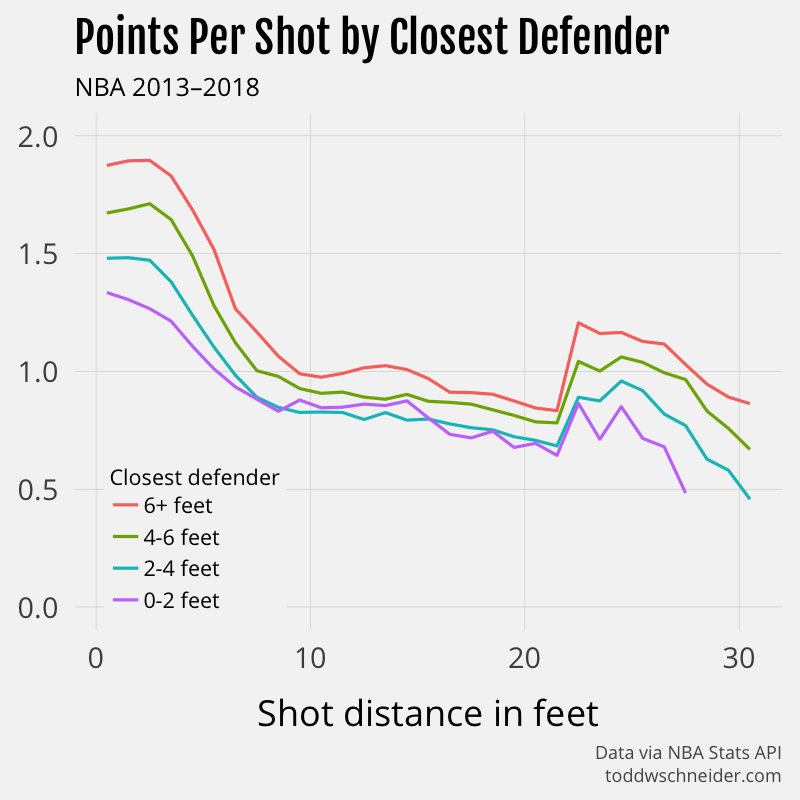



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}